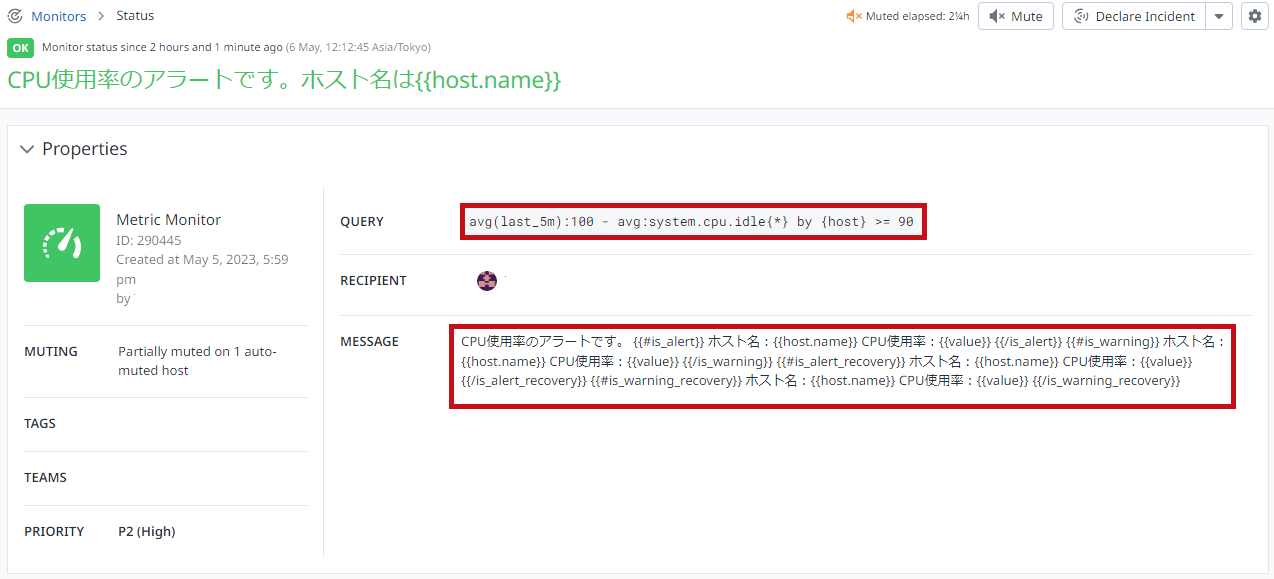
Datadogを使った仮想マシンのメトリクスや死活監視設定手順
Datadogを使った仮想マシン(Azure VM)のメトリクス(リソース)監視設定手順です。
死活監視やアラート通知メールの設定手順についても確認しています。
仮想マシンのリソース監視をDatadogで行う場合、主に以下の2つの方法があります。
-
- DatadogとAzureテナントを接続し、Azureのメトリクス情報を利用する方法
- 仮想マシンにインストールしたDatadog Agentでメトリクス情報を取得する方法
今回は、Datadog Agentを使った仮想マシンの監視設定手順を確認してみました。
仮想マシンの死活監視やCPU使用率を例に、メトリクス監視設定の手順をまとめています。
今回はAzure上の仮想マシンを利用していますが、オンプレやその他パブリッククラウドでも同じ手順で設定できます。
仮想マシンへのDatadog Agentインストール手順については、こちらで紹介しています。

※本記事では、Azure Virtual Machines(Azure VM)を仮想マシンとして表記しています。
Datadogを利用した仮想マシンの死活監視設定手順
アラートルールの作成手順
仮想マシンの死活監視を行うアラートルールを作成します。
Datadog Agentからの通信が停止した場合に検知できるように設定します。
-
- 監視設定で行う主な設定項目
- Pick hosts by name or tag:対象のホスト(例:しきい値監視)
- Set alert conditions:しきい値(例:監視間隔などのアラート発生条件)
- Notify your team:通知方法や内容(例:メール通知や通知本文)
- Define permissions and audit notifications:アラートルールの編集権限や、編集時の通知
- 監視設定で行う主な設定項目
| 仮想マシンの死活監視 | |
|
MonitorsのNew Monitorから新しいアラートルールを作成します。 |
 |
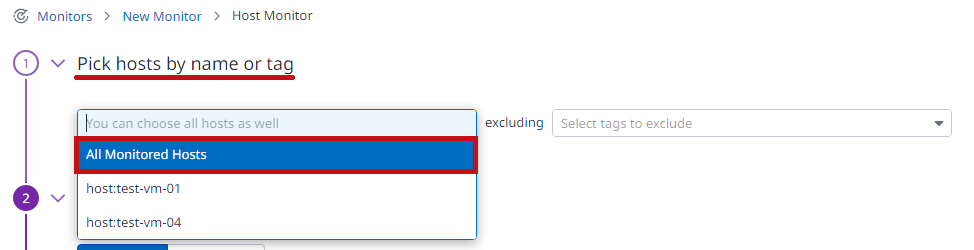
| Pick hosts by name or tagで対象のホストを選択します。 All Monitored Hostsを選択すると、すべての仮想マシンが監視対象になります。 |
 |
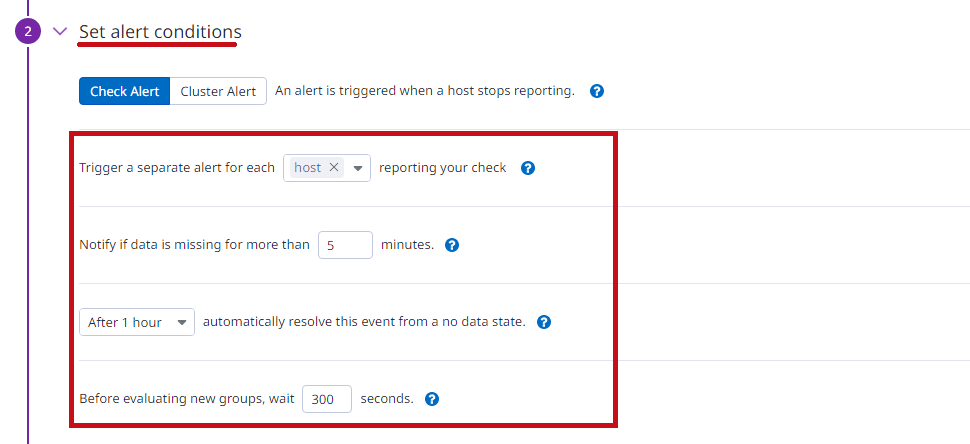
| Set alert conditionsでアラート発生条件を設定します。 5分以上通知がない場合にアラートが発生するように設定しています。 1時間後に自動的に解決されるようにしています。 |
 |
|
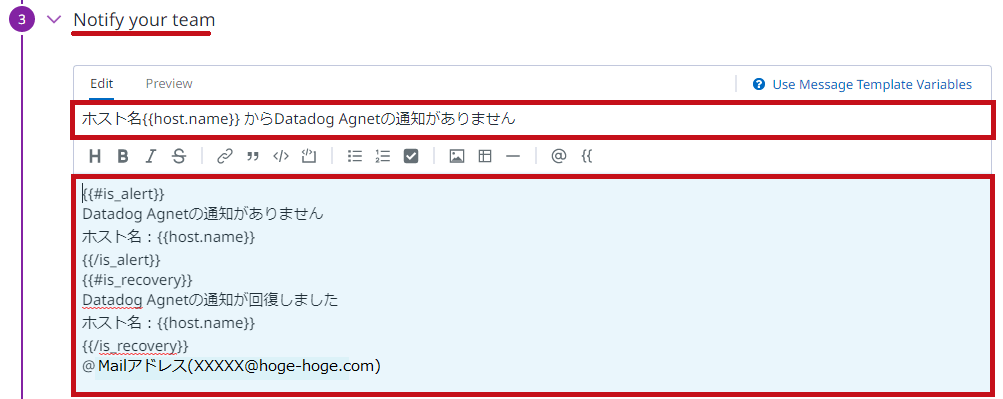
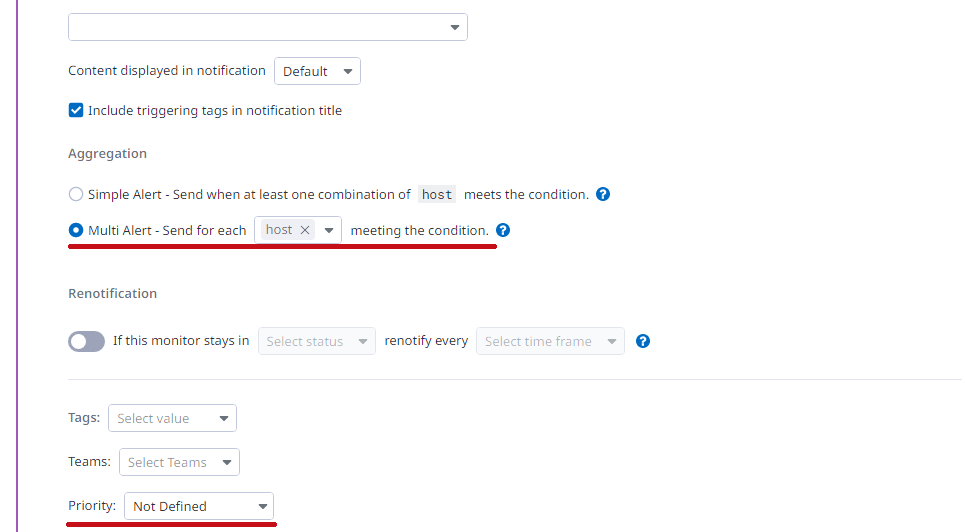
Notify your teamで通知方法や通知内容を設定します。 使用できる主な変数は以下の通りです。 @で通知先を指定します。 ※仮想マシン(ホスト)単位で通知が行われるため、Multi Alertとなっています。 |
 |
 |
|
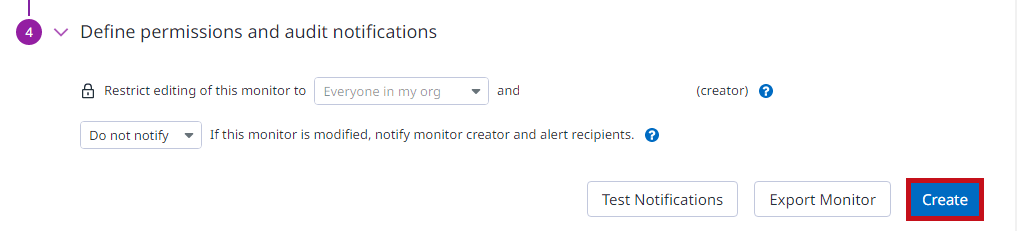
| Define permissions and audit notificationsでは、アラートの編集権限や設定変更時に通知するかどうかを指定できます。 今回はデフォルト設定(編集可、通知しない)のままとしています。 Createでアラートを作成します。 |
 |
アラート通知のテストメールを送信
アラートルール作成時にTest Notificationを選択すると、テストアラートメールを送信できます。
アラート発生時に通知される内容や通知先を確認できます。
| テストメールを送信 | |
| Test Notificationを選択します。 | 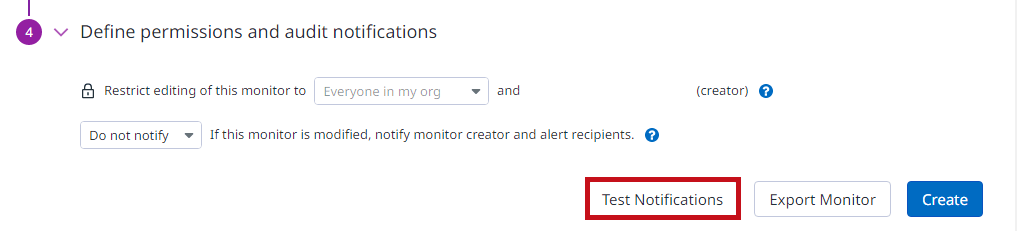 |
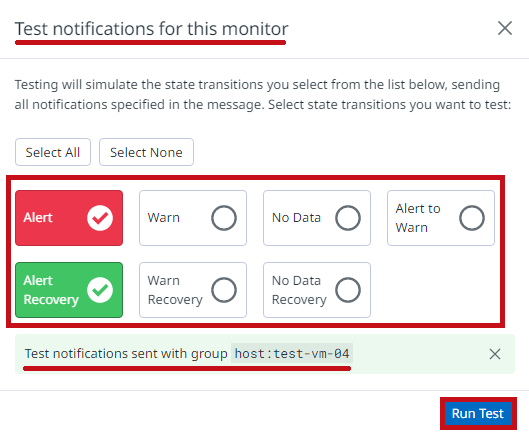
| 通知内容を選択します。 Run Testを選択すると、アラート通知が送信されます。 |
 |
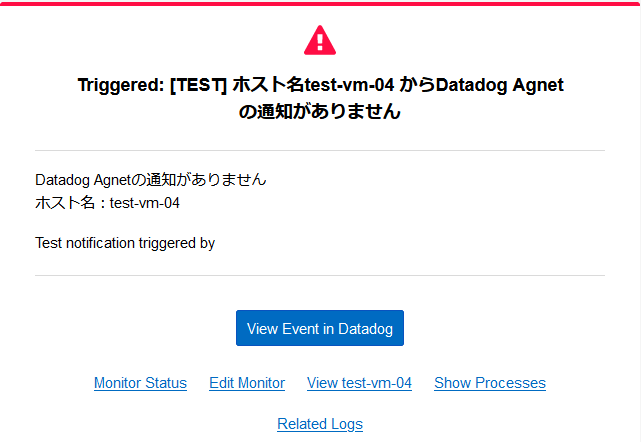
| アラート発生時と回復時のテストメールです。 設定内容通りに通知されていることが確認できます。 |
 |
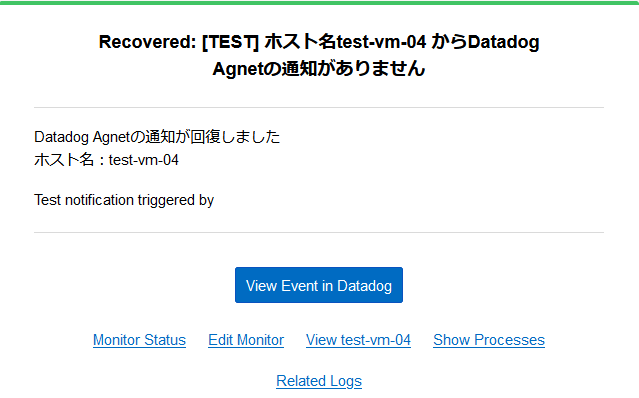 |
|
アラート通知メールの例
アラート発生時の通知メールの例です。
| アラートメール | |
|
アラート発生時および回復時に送信されるアラートメールの例です。 |
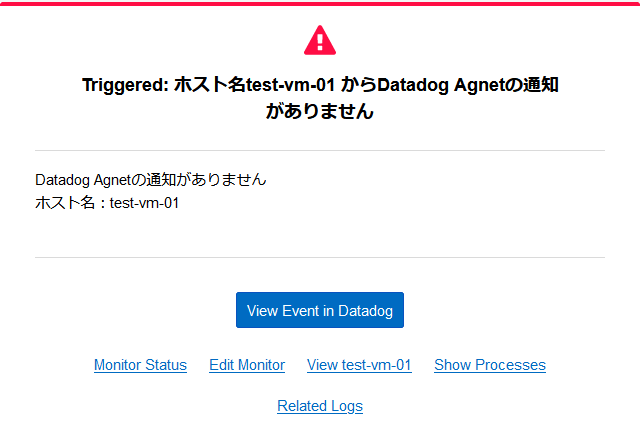 |
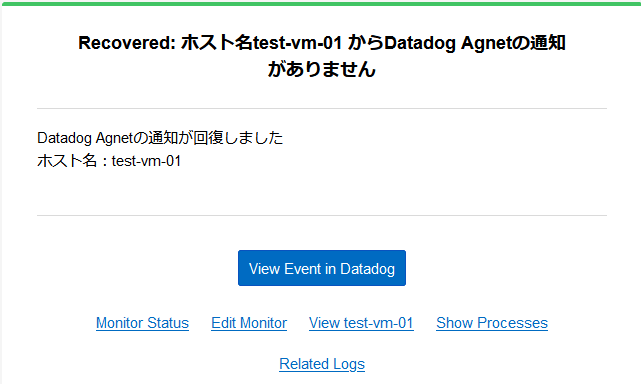 |
|
自動ミュートに注意
DatadogとAzureテナントを接続した監視方法を利用した場合の注意点です。
DatadogのIntegrationでAzureテナントと接続する際は、設定値に注意が必要です。
Monitor Automuting内のIntegration Silence monitor for expected Azure VM shutdownsにチェックを入れると、仮想マシンのシャットダウン時に自動的にミュート設定が適用されます。
この場合、Azure側で仮想マシンを停止してもアラート通知は送信されません。
ダウンタイム(manage downtime)に仮想マシンが自動的に登録され、ミュート(非通知)となります。
※ダウンタイムは永続的に設定されるため、仮想マシンを再起動した場合は、ダウンタイムから対象ホスト(サーバー)を手動で削除する必要があります。
—広告—
仮想マシンのメトリクス(リソース)監視設定手順
CPU使用率を監視するアラートルールを作成
Datadog Agentで取得できるメトリクスの項目については、公式サイトにまとめられています。
公式サイトの情報を参考に、CPU使用率の監視設定を進めます。
なお、監視設定項目には監視間隔は存在せず、監視評価期間のみ設定できます。
デフォルト値が設定されています。
-
- 監視設定で行う主な設定項目
- Choose the detection method:検出方法 (例: しきい値監視)
- Define the metric:監視項目や条件 (例: CPU使用率)
- Set alert conditions:アラート条件・閾値 (例: 90%以上でAlert)
- Say what’s happening:通知方法や通知内容 (例: Mail通知や本文)
- Define permissions and audit notifications:アラートルールの編集権限や、編集時の通知設定
| アラートルールを作成 | |
|
MonitorsのNew Monitorから新しいアラートルールを作成します。監視タイプにはMetricを選択します。 |
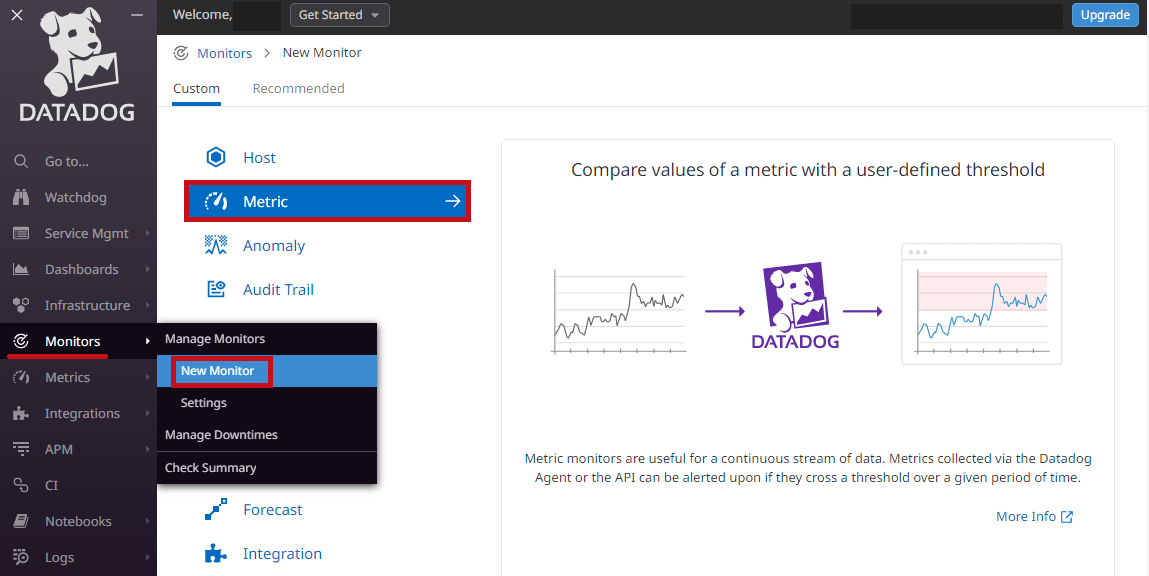 |
|
Choose the detection methodで検出方法を選択します。 CPU使用率はsystem.cpu.idleから算出しています。 avg byで集計単位を指定します。 |
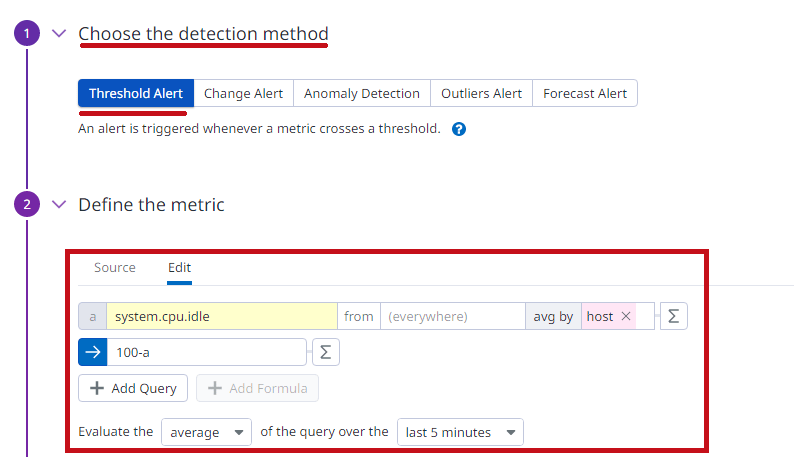 |
|
Set alert conditionsでアラート発生条件を設定します。 各種詳細項目については、こちらの解説を参考に設定します。 ※system.cpu.idleの値はパーセントで取得されます。 |
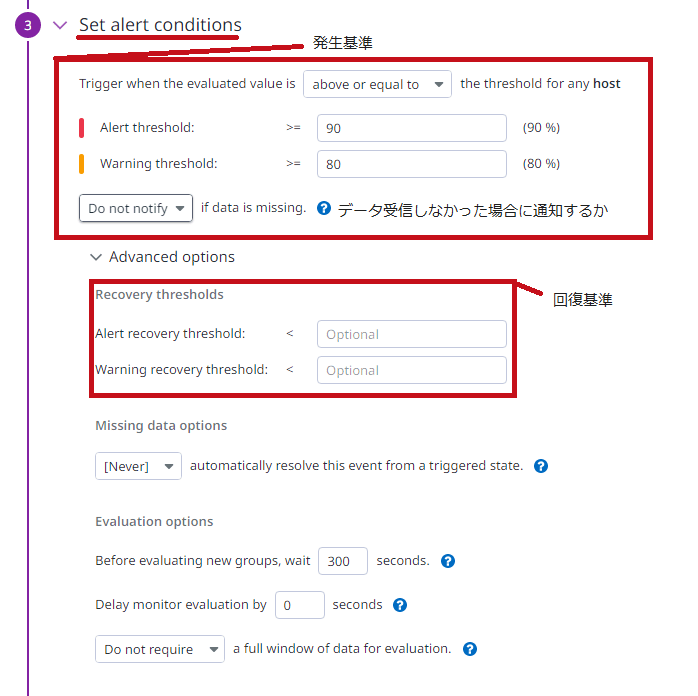 |
|
Notify your teamで通知方法や通知内容を設定します。 {{host.name}}:ホスト名 通知先は@で指定します。 ※ホスト(仮想マシン)単位での通知となるため、Multi Alertを選択しています。 |
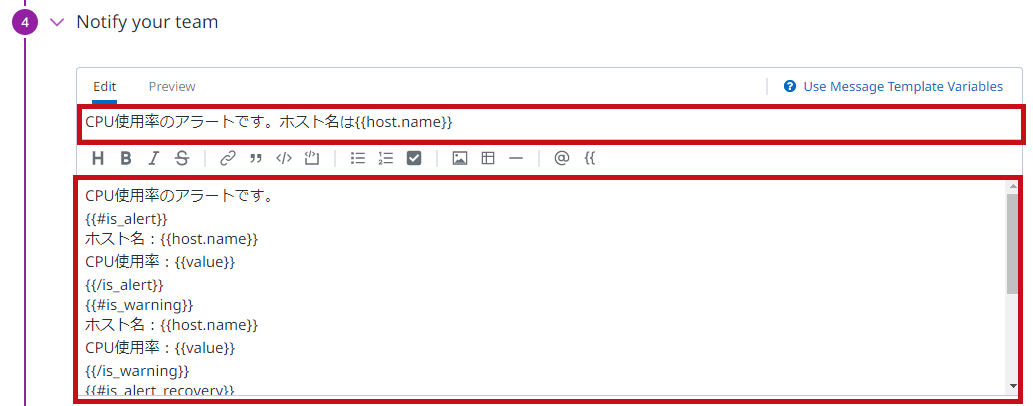 |
|
|
|
|
|
|
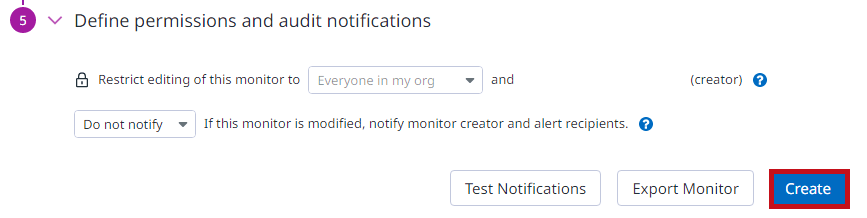
Define permissions and audit notificationsで、アラートの編集権限や設定変更時の通知有無を指定できます。 Createでアラートルールを作成します。 |
|
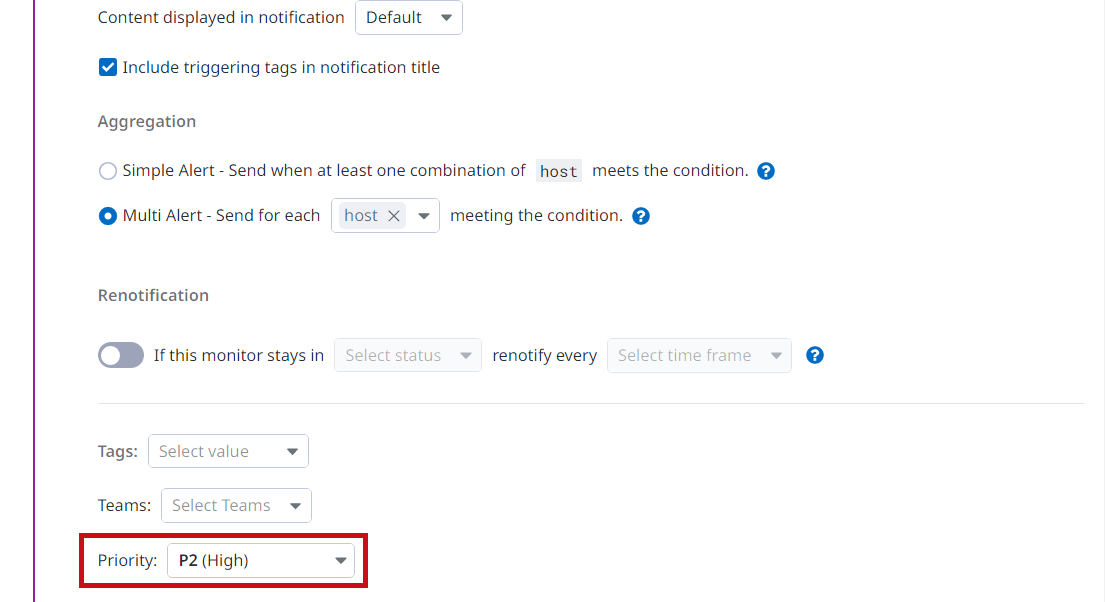
作成したアラートルールを確認
作成したアラートルールを確認します。
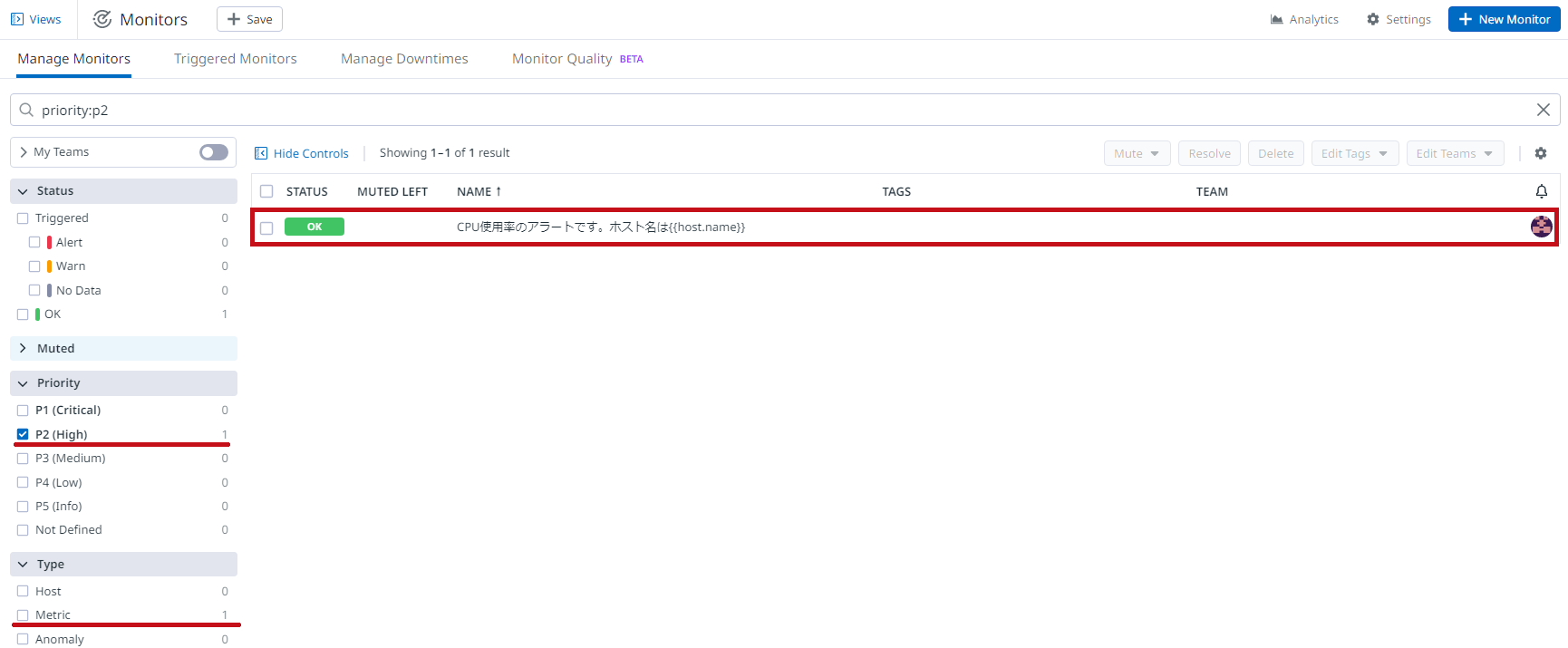
| アラートルールを確認 | |
| 作成したアラートルールはMonitorsで確認できます。 ルールのステータスも表示されます。 PriorityやTypeで絞り込みを行うことも可能です。 |
 |
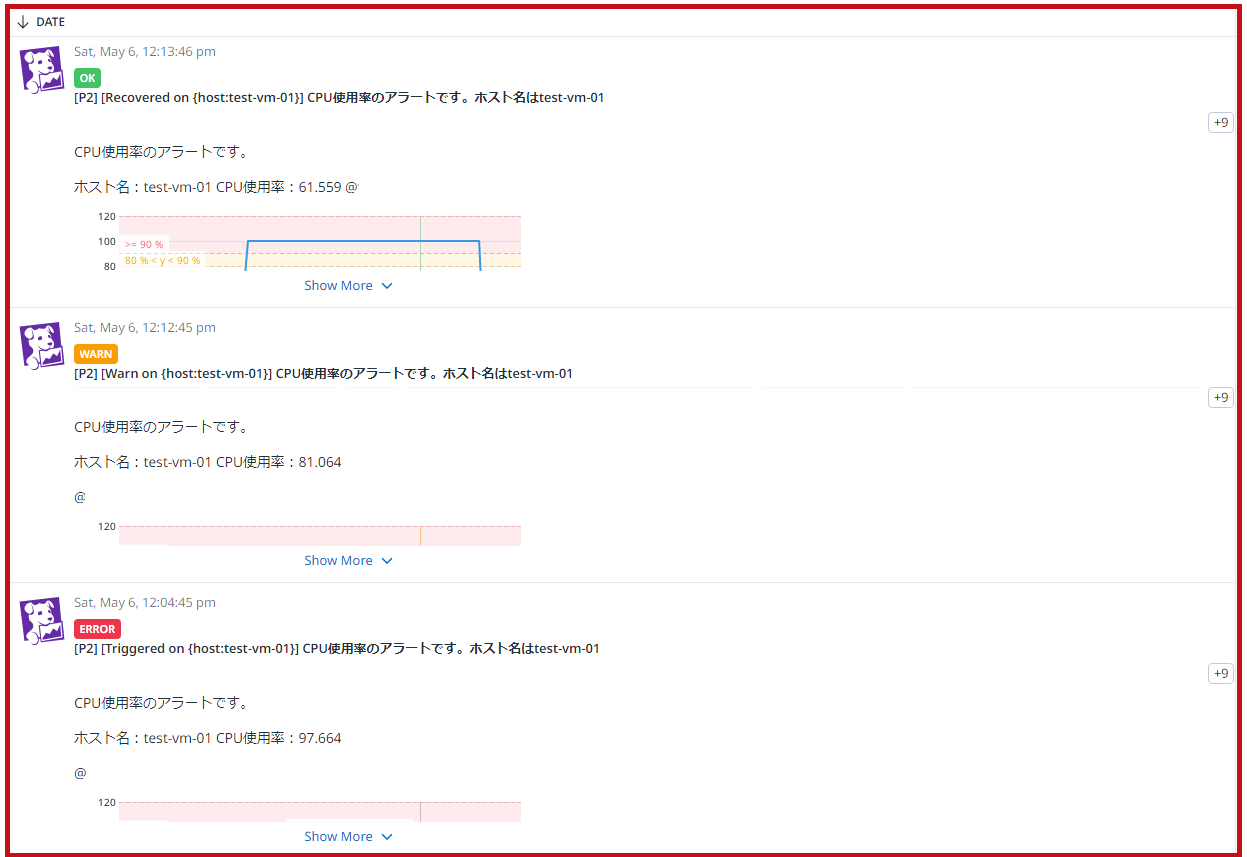
アラート通知メールの受信確認
仮想マシンでCPU使用率のアラートを発生させ、アラート通知メールが正しく受信できることを確認します。
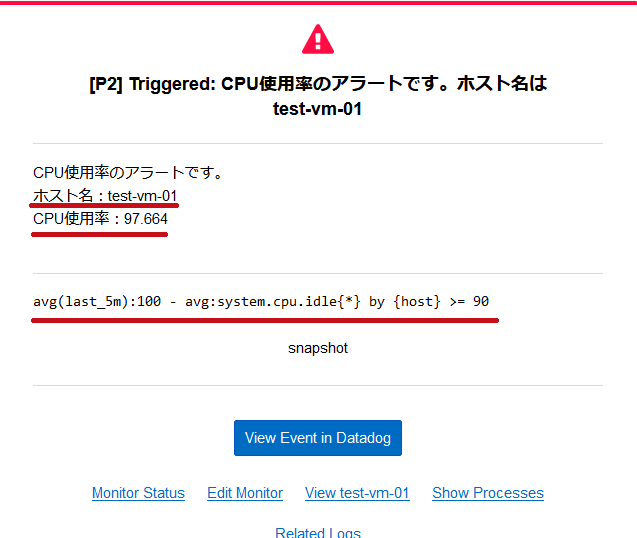
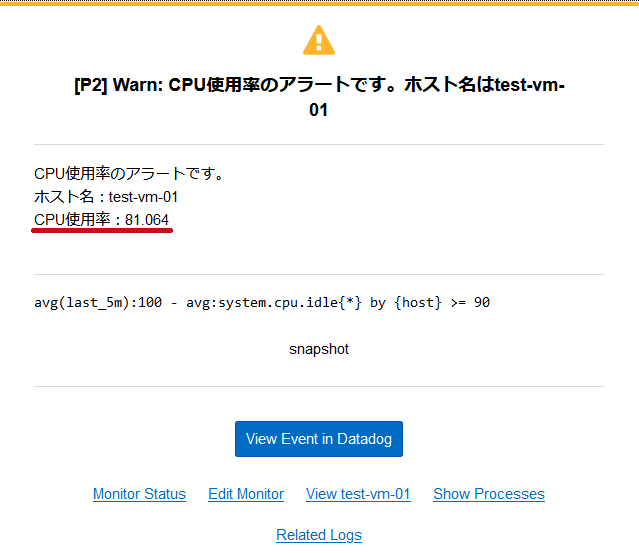
| アラート通知メールの受信確認 | |
| CPU使用率が90%以上になった時点でAlert、80%以上になった時点でWarningのメールを受信しています。 回復時のメールも受信できています。 メールにはCPU使用率の値も表示されています。 |
 |
 |
|
 |
|
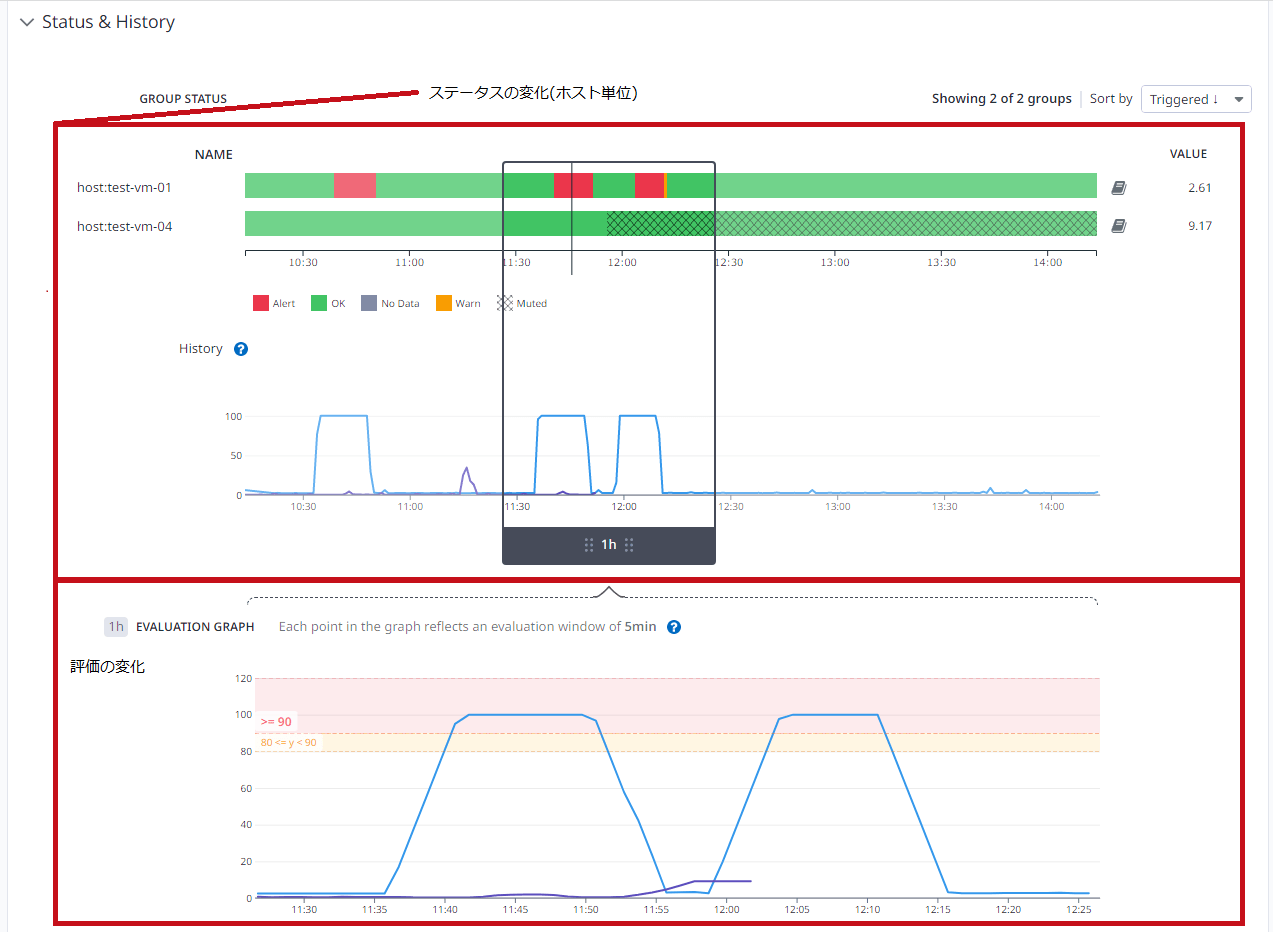
モニターステータスでメトリクスの変化を確認
モニターステータスでメトリクスの変化を確認します。
| ステータスの変化を確認 | |
|
現在のステータスだけでなく、ステータスの変化も確認できます。 |
 |
 |
|
 |
|
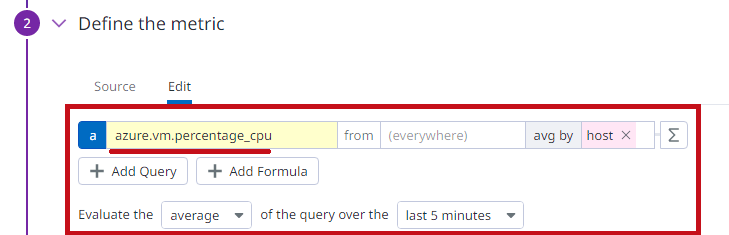
Azureのメトリクス値(CPU使用率)を使った設定
DatadogにAzureテナントを登録しておくことで、仮想マシンのメトリクス値も取得できます。
取得したメトリクス値を利用した監視設定も可能です。
DatadogへのAzureテナント登録手順は、こちらで紹介しています。
AzureとDatadogを接続して取得した値を利用する場合、データの遅延を考慮する必要があります。
| メトリクス値を指定 | |
|
項目はクラウド名.リソース種別.メトリクス値の形式で表示されます。 |
 |
メモリ使用率を監視するアラートルール
CPU使用率だけでなく、メモリ使用率も監視できます。
直接メモリ使用率に該当する項目がないため、取得された複数の値を組み合わせて計算し、監視を行います。
| メモリ使用率を監視 | |
|
system.mem.usableが空きメモリ容量、system.mem.totalが総メモリ容量に該当します。 |
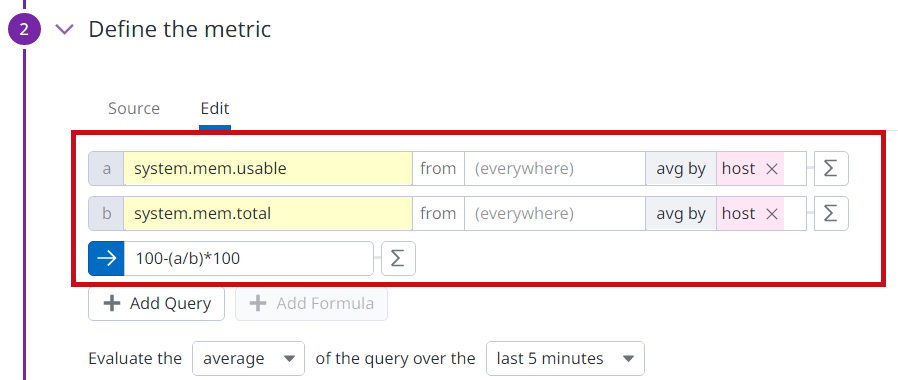 |
ディスク使用率監視を監視するアラートルール
ディスク使用率も監視できます。
デバイスごとに取得された値を利用します。
| ディスク使用率監視 | |
| system.disk.usedがディスク使用容量、system.disk.totalが総ディスク容量に該当します。 組み合わせて、ディスク使用率を計算します。 |
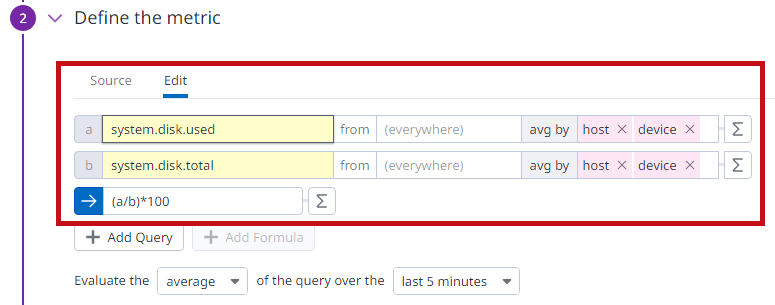 |
—広告—
最後に
Datadogのメトリクス監視設定からアラート通知までの手順について、仮想マシンのCPU使用率を例に確認してみました。
死活監視も含めた設定手順を確認しています。
今回は基本的な設定で実施しましたが、Datadogでは多種多様なメトリクスを取得でき、細かい設定も可能です。
取得対象のリソースや区分の設定も簡単に行えるため、非常に便利です。
アラート発生時にはSlack通知や、その他のインシデント管理ツールとの連携が可能な点も利便性が高いと感じます。
今回は実施していませんが、監視設定はエクスポートも可能です。
引き続き、いろいろ試してみたいと思います。
プロセスやサービス監視設定手順については、こちらで紹介しています。