Azure Application Gatewayのバックエンド正常性確認方法と監視設定手順
Azure Application Gatewayは、WEBアクセスをL7のレイヤーで負荷分散するロードバランサーです。
Azure Application Gatewayはバックエンドにあるホストの状態を監視し、正常な場合のみロードバランシングを行います。
WEBサービス状態の管理として、Azure Application Gatewayのバックエンドの状況を把握しておくことが重要です。
ロードバランシング先のホストへのアクセス状態は、バックエンド正常性としてAzure Portal上で確認することができます。
バックエンドの正常なホストの数はHealthy Host Countとして、異常なホストの数はUnhealthy Host Countのメトリックとして確認できます。
今回は、アプリケーションゲートウェイのバックエンド正常性監視方法についてまとめてみました。
Azure Application Gatewayの構築手順については、こちらで紹介しています。

※本記事では、一部を除きAzure Application Gatewayとして表記しています。メニュー上の表記でアプリケーションゲートウェイとある場合は、メニュー表記に合わせて表記しています。
Azure Application Gatewayのバックエンド正常性を確認する方法
以下のAzure Application Gatewayを使用して確認しています。
-
- リソース名:agw-test-01
- リソースグループ名:RG-AGW-TEST-01
- バックエンドプール名:Backend-pool-01
- バックエンド設定名:Backend-setting-01
Azure Portalでバックエンド正常性を確認
バックエンドの正常性のメニューが用意されています。
| Azure Portalでバックエンド正常性を確認 | |
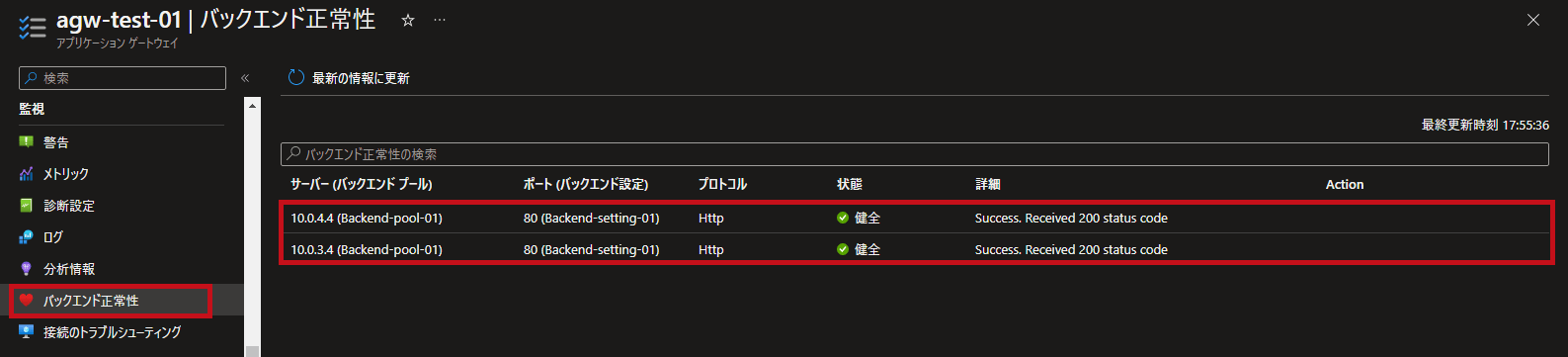
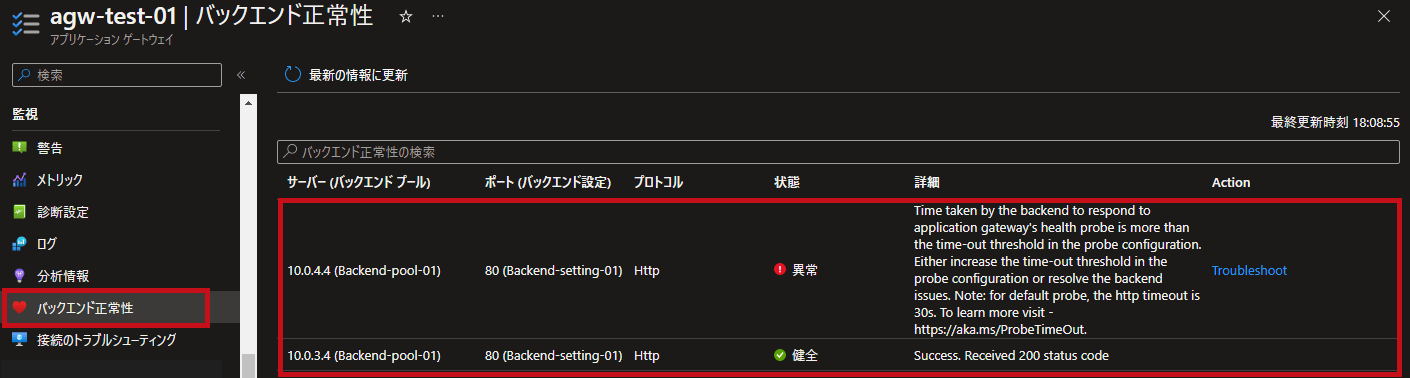
| ホスト(サーバー)単位でバックエンドの正常性を確認できます。 異常時はエラー内容を表示してくれます。 |
【正常時】
|
|
【異常時】
|
|
メトリックでバックエンド正常性を確認
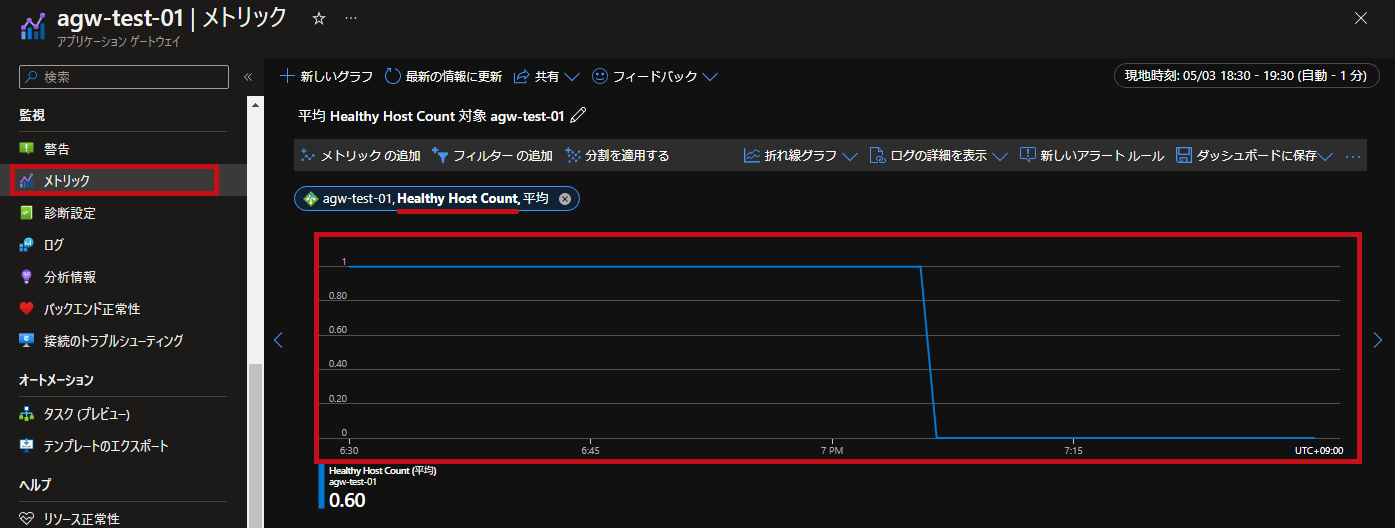
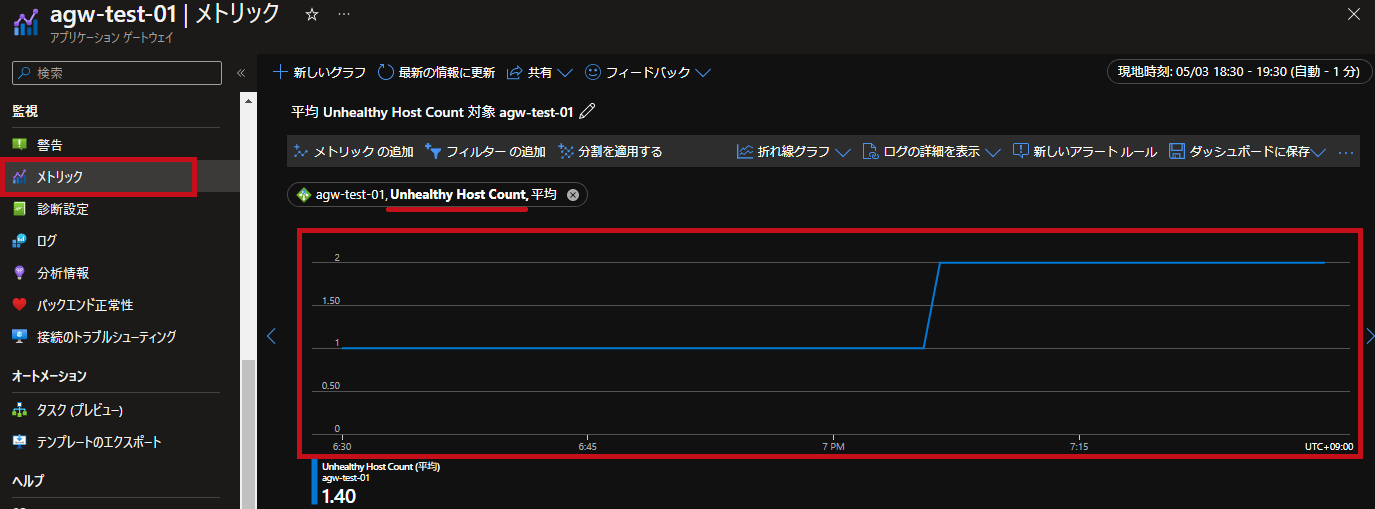
バックエンド正常性に関連するメトリックとして、正常なホストの数 (Healthy Host Count) と異常なホストの数 (Unhealthy Host Count) があります。
それぞれバックエンドプール内のホストのステータスごとの数を示しています。
画面例は、バックエンドのサーバー2台のうち1台が異常な状態から、2台とも異常になった場合の例です。
| メトリックでバックエンド正常性を確認 | |
| 正常なホストの数 (Healthy Host Count) の例です。 途中で、正常な状態のホストが0になっていることが確認できます。 |
 |
| 異常なホストの数 (Unhealthy Host Count) の例です。 途中で、異常なホストが1台から2台に増えたことが確認できます。 |
 |
PowerShellでバックエンド正常性を確認
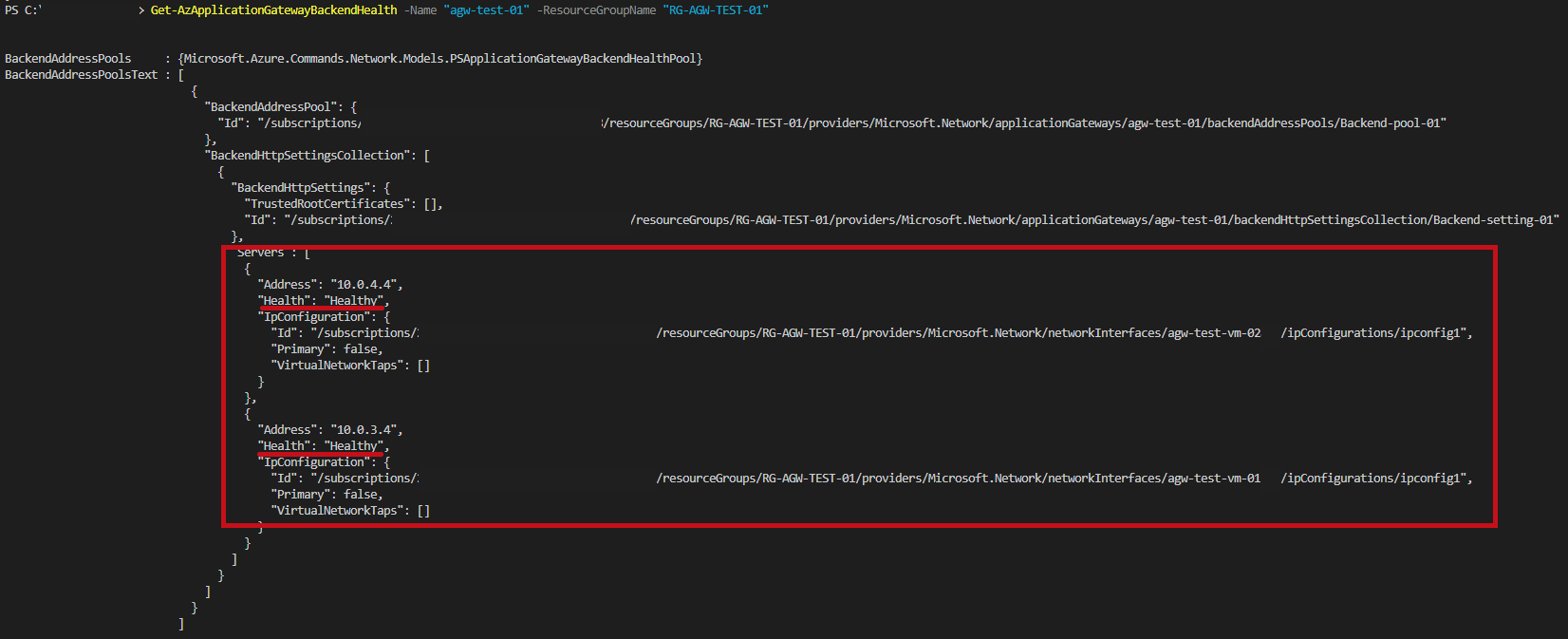
PowerShellでバックエンド正常性を確認をする場合は、Get-AzApplicationGatewayBackendHealthコマンドレットを使用します。
Get-AzApplicationGatewayBackendHealth
| PowerShellで確認 | |
|
|
 |
Azure CLIでバックエンド正常性を確認
Azure CLIでバックエンド正常性を確認をする場合は、az network application-gateway show-backend-healthを使用します。
az network application-gateway show-backend-health
| Azure CLIで確認 | |
|
—広告—
Azure Monitorでバックエンド正常性を監視するアラートルールを作成
アラートルールの設定値
今回は、バックエンドに配置するホストを2台としています。
異常なホストの数 (Unhealthy Host Count) と正常なホストの数 (Healthy Host Count) をそれぞれ監視するアラートルールを作成します。
-
- 異常なホストの数(Unhealthy Host Count)を監視
- アラールール名:AGW Unhealthy Host Count
- 条件:異常なホストの数が5分平均で0より大きい場合
- 正常なホストの数(Healthy Host Count)を監視
- アラールール名:AGW Unhealthy Host Count
- 条件:正常なホストの数が5分平均で1より小さい場合
- 異常なホストの数(Unhealthy Host Count)を監視
| アラートルール名 | 異常なサーバーの数 | ||
| 0台 | 1台 | 2台 | |
| AGW Unhealthy Host Count | × | 〇 | 〇 |
| AGW Healthy Host Count | × | × | 〇 |
異常なホストの数(Unhealthy Host Count)を監視するアラートルール
異常なホストの数を監視することで、バックエンドのサーバーで異常が発生したことを検知できます。
今回は、サーバー1台以上に異常が発生した場合にアラートを検知するように設定しています。
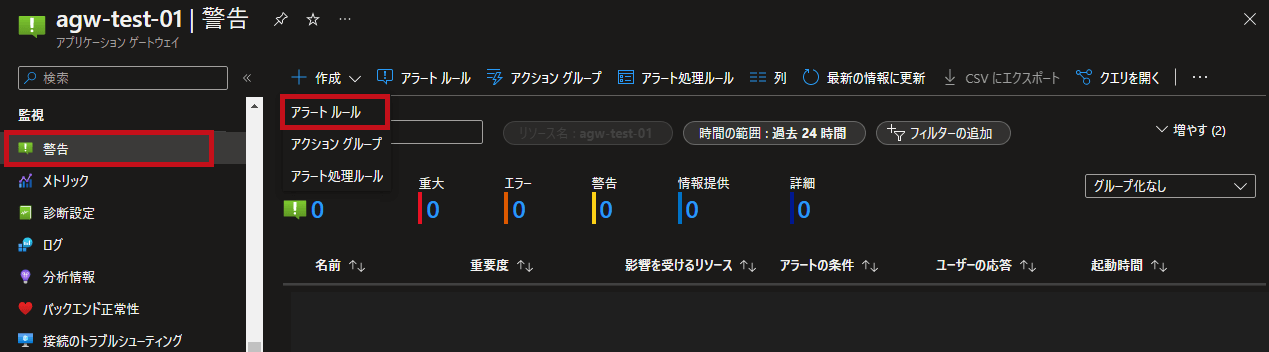
| アラートルールを作成 | |
| アプリケーションゲートウェイのリソースメニューで警告を選択します。 作成でアラートルールを選択します。 |
 |
| シグナルの選択でUnhealthy Host Countを選択します。 | 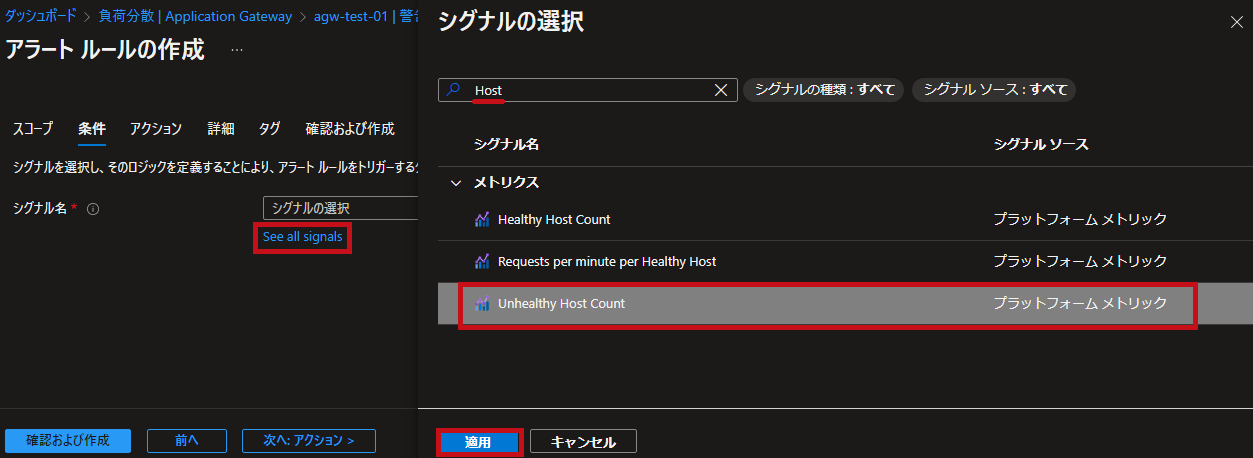 |
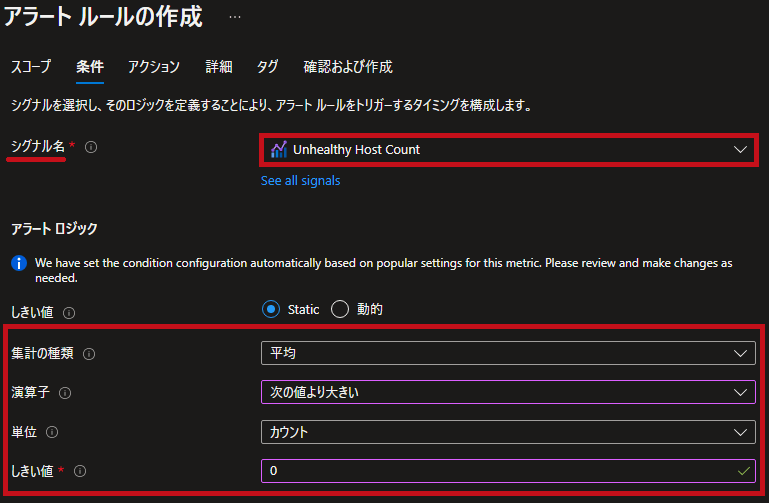
| 条件設定です。 アラートロジックを0より大きい場合とします。 |
 |
|
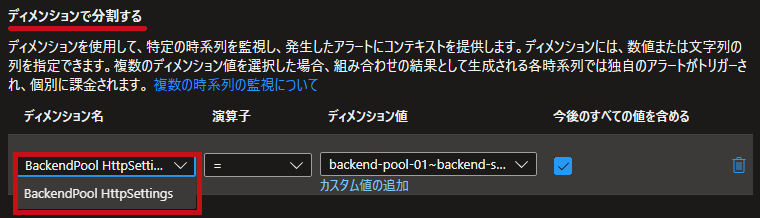
ディメンションの分割ではBacendPool HttpSettingsを選択します。 |
 |
| 評価するタイミングはそれぞれ5分としています。 |  |
|
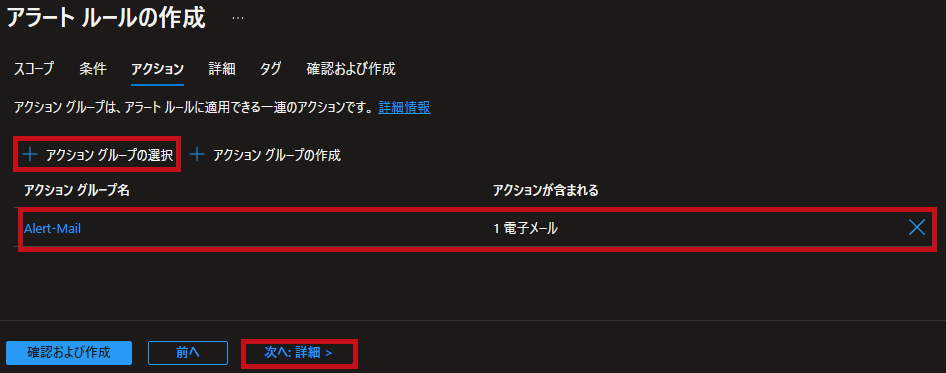
アクショングループでアクショングループを選択します。 |
 |
|
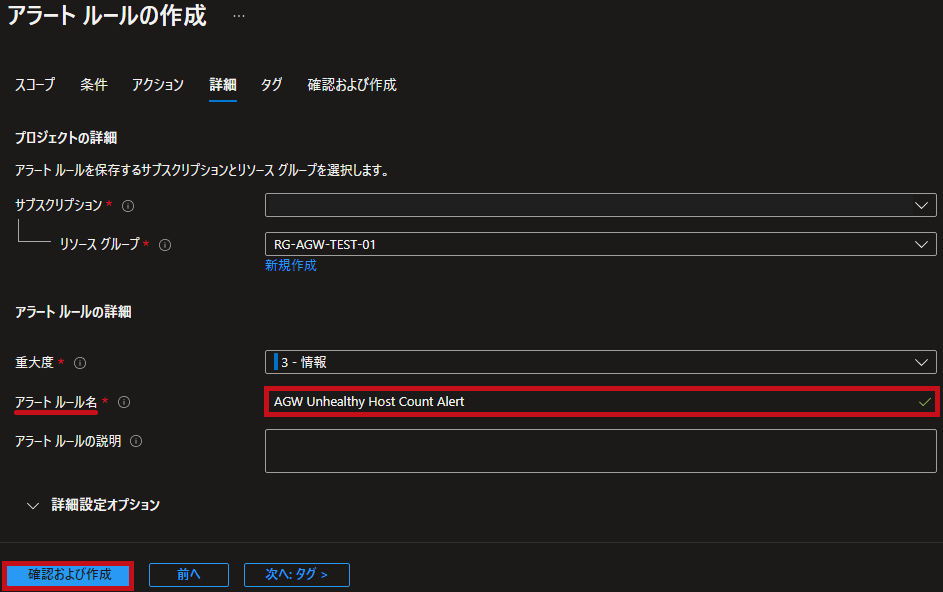
詳細の設定です。
|
 |
正常なホストの数(Healthy Host Count)を監視するアラートルール
正常なホストの数を監視することで、バックエンドのサーバーが一定数を下回った場合(全台停止など)に異常が発生したことを検知できます。
今回は、正常なサーバーがなくなった場合(平均が1を下回った場合)にアラートを検知するように設定しています。
| アラートルールを作成 | |
| アプリケーションゲートウェイのリソースメニューで警告を選択します。 作成でアラートルールを選択します。 |
|
| シグナルの選択でHealthy Host Countを選択します。 | 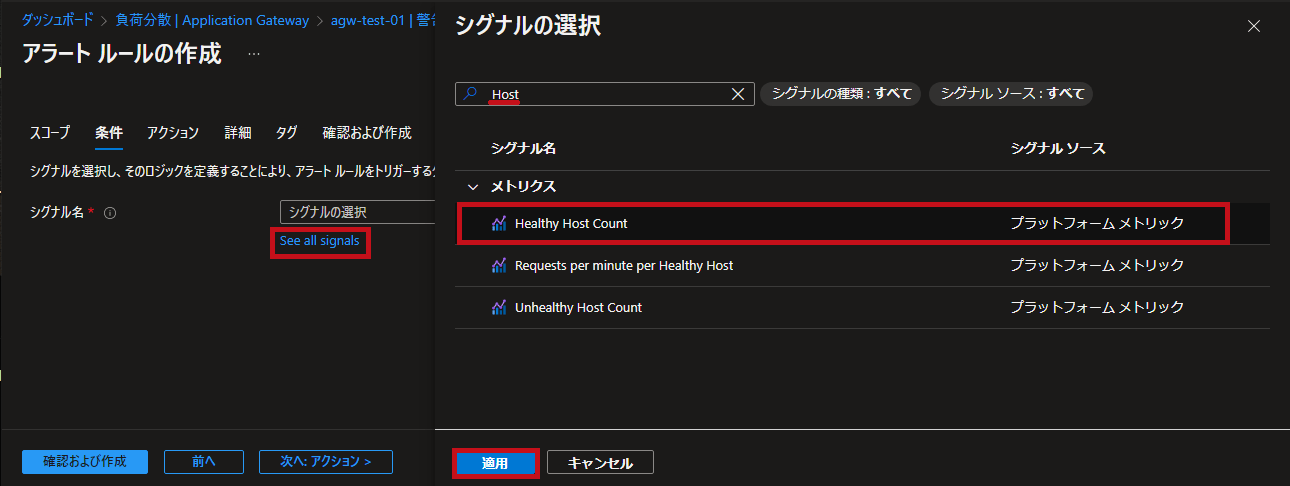 |
| 条件設定です。 アラートロジックを1より小さい場合とします。 |
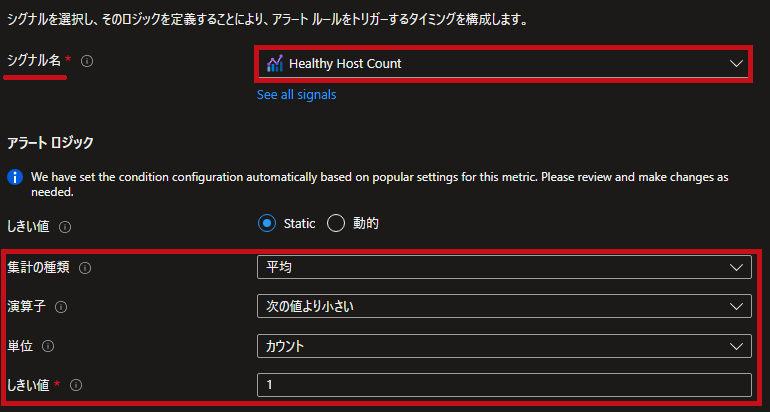 |
|
ディメンションの分割ではBacendPool HttpSettingsを選択します。 |
|
| 評価するタイミングはそれぞれ5分としています。 | |
|
アクショングループでアクショングループを選択します。 |
|
|
詳細の設定です。 |
 |
作成したバックエンド正常性を監視するアラートルール
作成したアラートルールを確認します。
| アラートルール一覧 | |
| アラートルールが2つ作成されていることを確認できます。 | 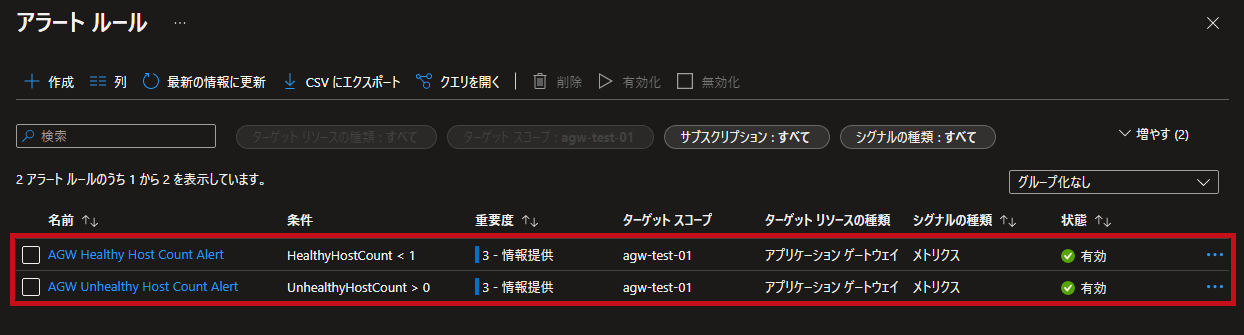 |
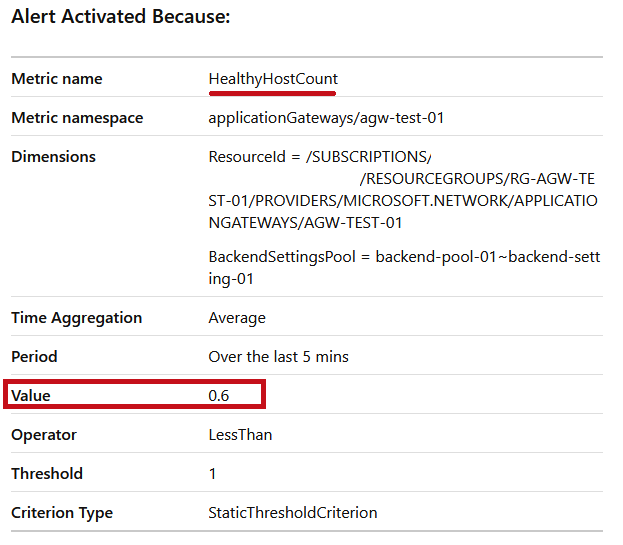
アラートを検知した場合のメール通知例
アラートルール(AGW Healthy Host Count)を検知した場合です。
正常なホストの数(Healthy Host Count)が0台になった場合に、アラートメールが送信されます。
| アラートメールの例 | |
| Healthy Host Countが5分間の平均で1以下になっていることが、メール本文で確認できます。 | 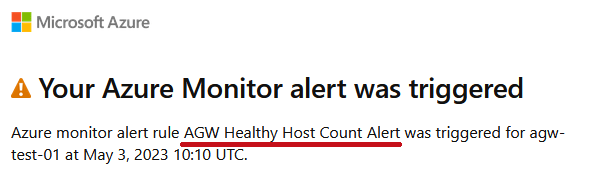 |
 |
|
—広告—
最後に
Azure Application Gatewayのバックエンド正常性確認方法からAzure Monitorの監視設定までをまとめてみました。
バックエンドの正常性は、Azure PortalやAzure PowerShell、Azure CLIなどで確認できます。
正常なホストの数(Healthy Host Count)や異常なホストの数(Unhealthy Host Count)のメトリックでも確認できました。
このメトリックを使って、バックエンド正常性の変化やサービス停止を検知することができました。
引き続き、いろいろ試してみたいと思います。
Azure Application Gatewayのカスタムエラーページ設定手順については、こちらで紹介しています。
Azure Front Doorのバックエンド正常性監視については、こちらで紹介しています。
Azure Application Gatewayのパスベースルーティング規則を使ったサーバー振り分け設定については、こちらで紹介しています。